Activation Functions
Activation functions define how the output of a neural network node is calculated based on its inputs. This library provides several activation functions for NEAT neural networks.
Built-in Functions
Sigmoid
S-shaped function that maps any input to a value between 0 and 1. Often used for outputs that represent probabilities.
Formula: σ(x) = 1 / (1 + e-x)
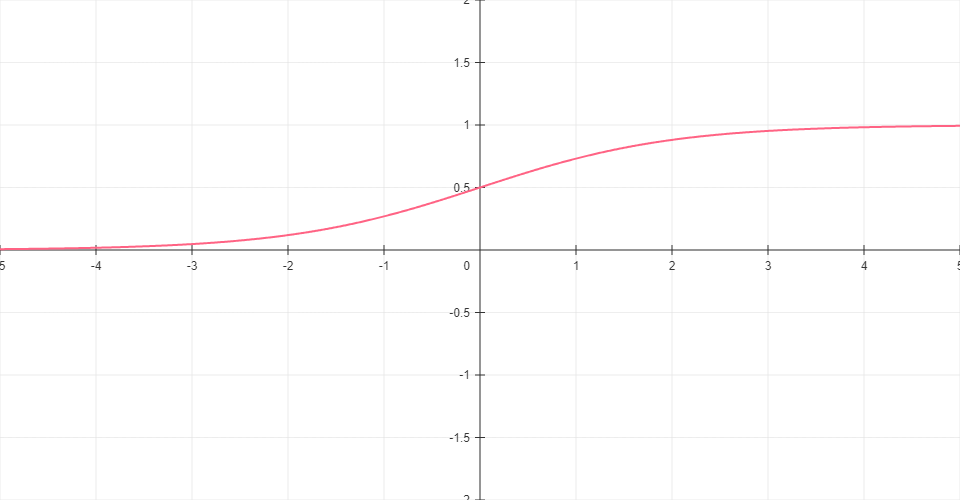
Range: (0, 1)
NEAT Sigmoid
Modified sigmoid function from the original NEAT paper with a steeper slope. Uses a coefficient of 4.9 to create a sharper transition.
Formula: σ(x) = 1 / (1 + e-4.9·x)
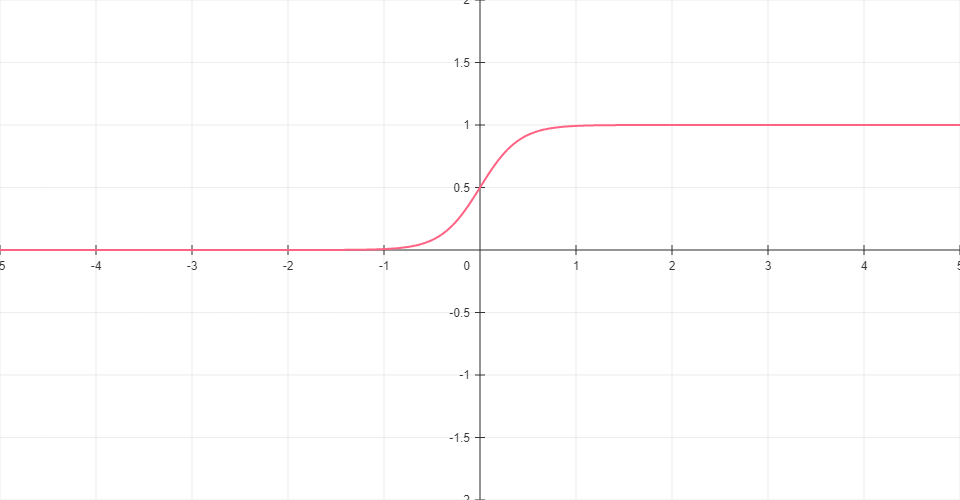
Range: (0, 1)
Tanh
Hyperbolic tangent function that outputs values between -1 and 1. Zero-centered, making it useful for problems requiring negative values.
Formula: tanh(x) = (ex - e-x) / (ex + e-x)
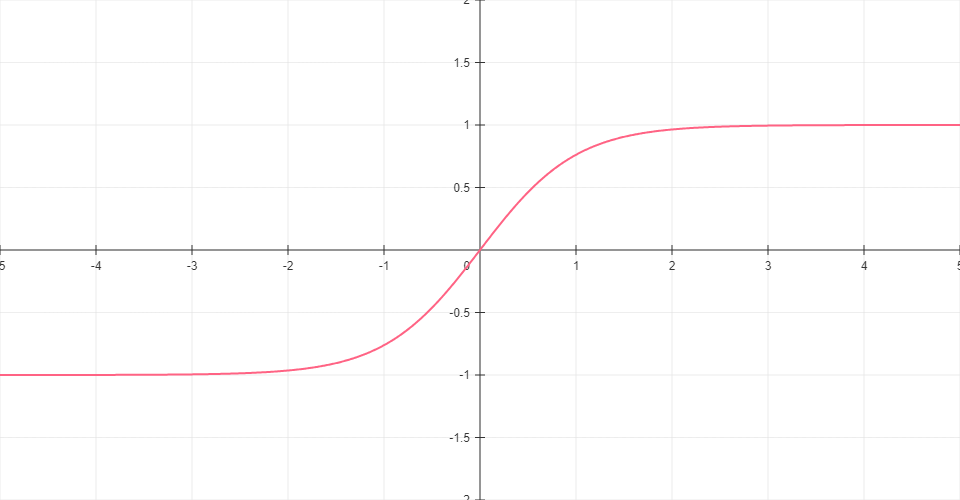
Range: (-1, 1)
ReLU
Rectified Linear Unit passes positive inputs unchanged and turns negative inputs to zero. Computationally efficient with no upper bound.
Formula: ReLU(x) = max(0, x)
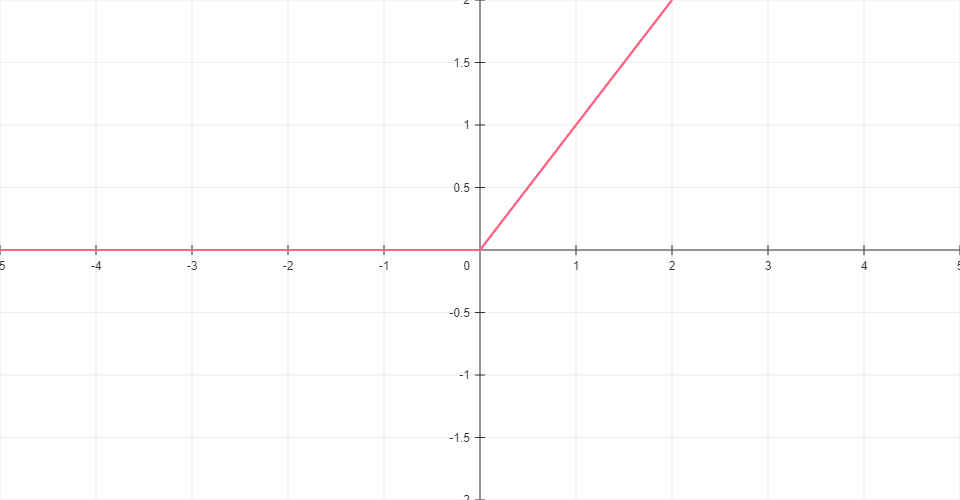
Range: [0, ∞)
Leaky ReLU
Variant of ReLU that allows small negative values (multiplied by 0.01) when the input is negative, preventing neurons from becoming inactive.
Formula: LeakyReLU(x) = max(0.01x, x)
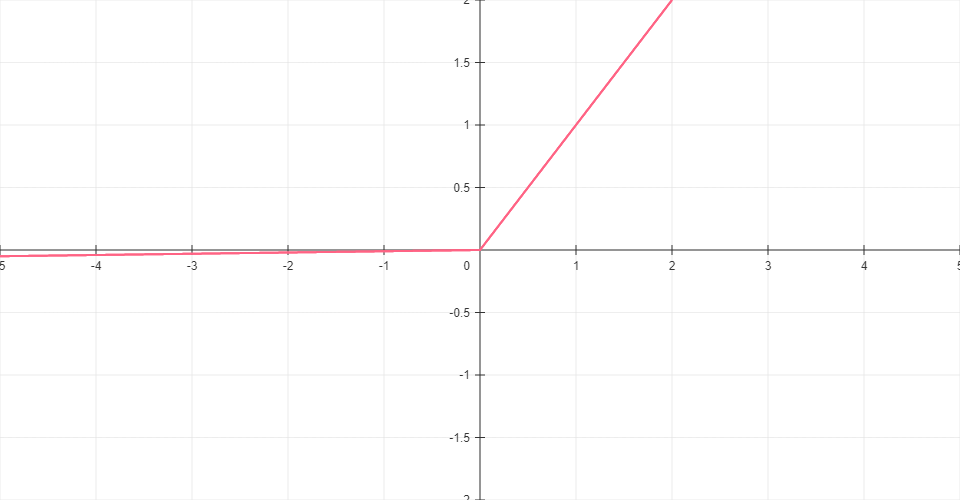
Range: (-∞, ∞)
Gaussian
Bell-shaped function that outputs its maximum value at zero and decreases as input moves away from zero in either direction. Useful for radial basis function networks.
Formula: G(x) = e-x²
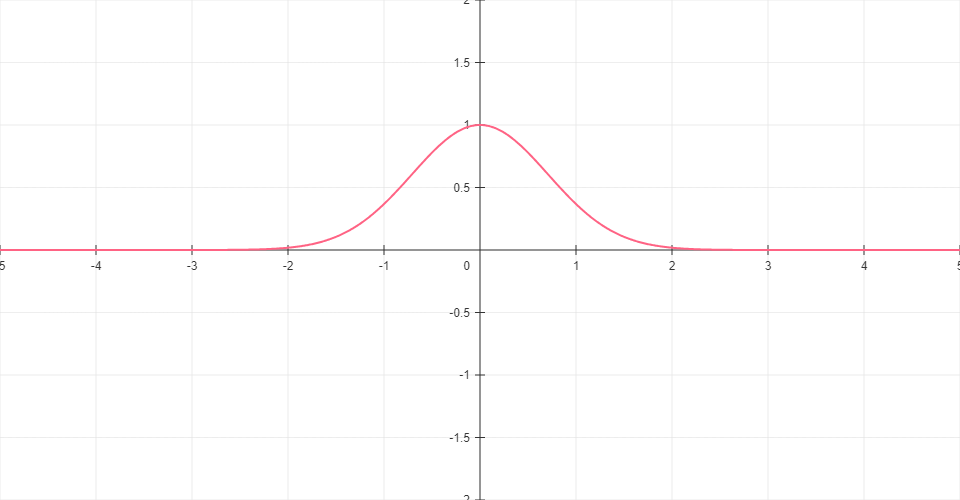
Range: (0, 1]
SELU
Scaled Exponential Linear Unit combines scaling factors with exponential behavior for negative inputs. Designed to maintain activation distributions through network layers.
Formula: SELU(x) = λ * (x if x > 0 else α * (ex - 1))
where λ ≈ 1.0507 and α ≈ 1.6733
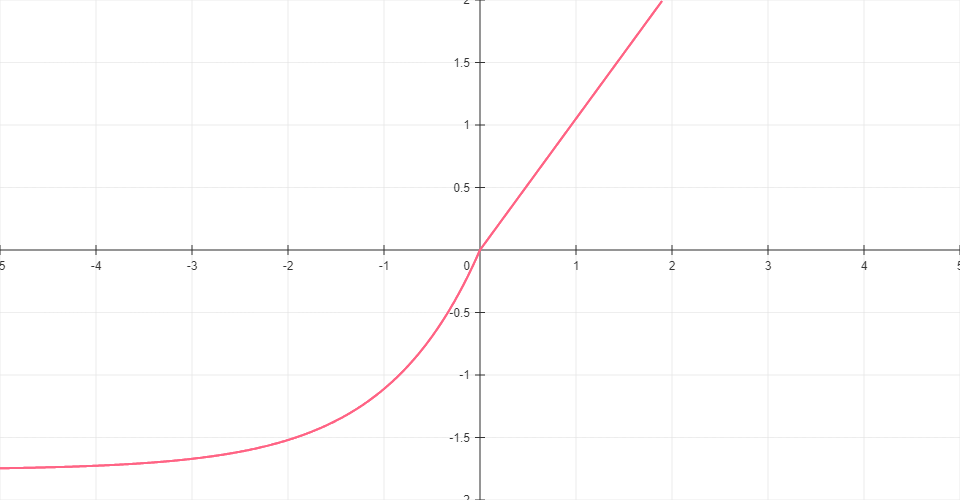
Range: (λ * α - λ, ∞)
Custom Activation Functions
Create custom activation functions by implementing a class with an apply method.